
Surprising discoveries (#5)
ADHD TikTok, AI dialing 9-1-1, the world's most concentrated religion, and rankings.


Metrics and Value Capture
(Longer version of a note I posted this week)
Metrics don’t just express values, but create them — a process of “value capture” as philosopher C. Thi Nguyen terms in his new book. Over-indexing on metrics confuses the goal (e.g. winning the game) with purpose (e.g. having fun). But at the same time, rankings compress information usefully which draws attention and coordinates action (e.g. sending poverty aid where it’s most needed).
A good example is the measurement of corruption. Because corrupt acts occur behind closed doors, systematic measurement helps make an otherwise invisible problem visible. Without it, claims about corruption collapse into anecdotes or isolated cases rather than something that can be compared across countries, regions, and time. The recently released Corruption Perceptions Index, in particular, does a good job of measuring many aspects of the construct known as corruption, creating a full and accurate portrait of an unobservable phenomenon — even if it is ultimately distilled to a single number (a ranking).
I’ve spent a lot of time thinking (and writing) about this in the context of college rankings, which is perhaps the original sin of ‘one-size-fits-all’ value capture. One of the fundamental conclusions from my research at NORC is that even if you agree with the ‘default value set’ implicated by a set of metrics and the metrics are ‘correct’ in a technical sense, and they expansively cover all aspects of the college experience — there’s a huge amount of uncertainty that pretty much no ranking (or really any major ‘pop metric’) today is willing to admit.

Part of it is because institutions contain multitudes, unlike games with literal scoreboards where you’re either winning or losing. But part of it is because the world is random and winners are sometimes flukes. All uncertainty considered, #1 and #2 are often not actually different and we would go about our lives a little less clenched, sweaty, and stressed knowing this to be true.
And, of course, sharing this post itself is a small performance of metrification, where on this new Substack-as-Twitter, every idea becomes an exercise of profilicity. As I’ve admitted before, and as it’s been written by others, the platform’s new dynamics kind of suck.
Surprising Discoveries
Half of ADHD TikTok is inaccurate. Researchers evaluated popular TikTok videos about ADHD and found that fewer than 50% of the claims about symptoms actually aligned with the diagnostic criteria used in clinical psychology. The videos were wildly popular nonetheless, collectively drawing nearly half a billion views. (Karasavva et al. / PLOS One / featured on Vox “Explain It to Me”)
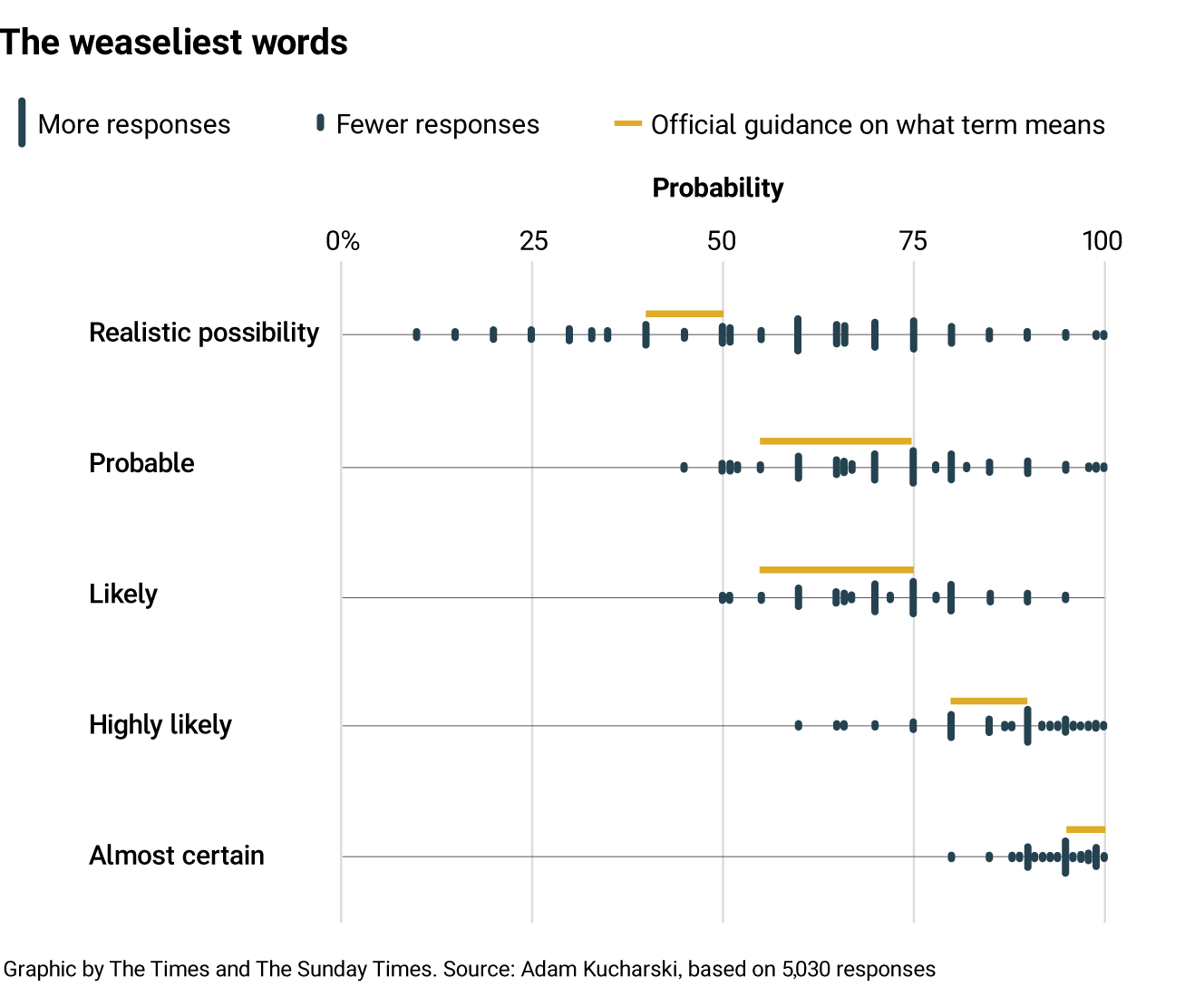
Probabilistic phrases like “serious possibility” mean wildly different things to different people. In a large online quiz with more than 5,000 participants, interpretations of probability phrases (or ‘weasly words’) varied dramatically. One phrase — “realistic possibility” — was interpreted as anything from a 10% chance to a 100% chance. Even intelligence analysts in the Cold War struggled with the same ambiguity. (Adam Kucharski / The Times)
ChatGPT won’t call the ambulance. In a structured test using clinician-written medical scenarios, an AI triage system under-triaged more than half of true emergency cases, sometimes advising patients with conditions like diabetic ketoacidosis to seek care within 24–48 hours rather than go to the emergency department. For the AI skeptics who are rolling their eyes with boredom, what perhaps is surprising here is failures were especially common at the extremes, both clearly non-urgent and clearly urgent cases. (Ramaswamy et al / Nature Medicine)
A simple text message can keep many people from missing court. Millions of Americans miss court dates each year, often because they simply forget according to a body of research. Across 12 studies, automated text reminders consistently improved attendance, reducing missed hearings by anywhere from 12% to 53%. (Isabel Shapiro / Pew)
Asian American voters will cross party lines, but only for co-ethnic Asian candidates. Survey experiments show that Asian American voters prioritize descriptive representation, preferring co-ethnic candidates even over co-partisan ones. However, that willingness to cross party lines disappears for broader pan-ethnic candidates. (Cho, Costa, and Horiuchi / British Journal of Political Science)
People say they prefer human empathy, but rate AI empathy higher. Across multiple studies, participants reported that they would rather receive empathy from a human. Yet when they actually evaluated responses, they rated AI-generated empathetic messages as higher quality, more effective, and more effortful. (Wenger, Cameron & Inzlicht / Communications Psychology)
Hinduism is the world’s most geographically concentrated religion … and no other religion even comes close. About 95% of the world’s 1.2 billion Hindus live in India. Meanwhile, two-thirds of the world’s 1.9 billion religious “nones” live in a single country: China. (Conrad Hackett / Pew Research Center)
Most firms now use AI, but only a little, and there are large gaps in expectation and disagreements about impact. A survey of nearly 6,000 executives found that around 70% of firms report actively using AI. Yet the typical executive uses it only about 1.5 hours per week, and one quarter report no use at all. Interestingly, those same executives predict sizable impacts over the next 3 years, forecasting AI will boost productivity by 1.4% and cut employment by 0.7% . Even more interestingly individual employees do not share this review and rather predict a 0.5% increase in employment in the next 3 years as a result of AI. Who will be correct? (Yotzov et al / NBER)
People judge wrongdoing less harshly for “bad victims”. Across four preregistered experiments, participants punished perpetrators less severely when their victims had previously committed immoral acts. The perpetrators in the scenarios did not know this information — suggesting the effect comes from people assuming that “bad” victims suffer less. It should be noted that the effects are quite small .. but interesting and surprising nonetheless. (Inbar et al / Cognition)
Some AI models are much more willing than others to call out nonsense. A benchmark testing “bullshit detection” found large differences across models. Some systems readily challenge flawed or incoherent prompts — with Anthropic’s Claude models squarely leading the pack — while others confidently generate answers to questions that make little sense at all — particularly older GPT models. (Peter Gostev / BullshitBench)
