
Surprising discoveries (#7)
AI metaphors, data center costs, the vacuum of USAID, and what LLMs think are obvious


Surprising discoveries
Cutting USAID immediately increased armed conflict in Africa. An empirical analysis of real-time conflict data (ACLED) found that the 2025 USAID suspension was followed by roughly a 5% increase in both conflict events and fatalities across Africa. The proposed mechanism: disruption to the state–armed group power balance shifted incentives toward short-term violence, while the economic hit to local communities lowered the opportunity cost of joining armed groups. What’s amazing is that this paper is one of the first to use live conflict data to measure the immediate downstream effects. (Tan, Amarasinghe & Ubilava / NBER)
Only 37% of Americans believe federal statistics are generally accurate. A NORC survey conducted for the American Statistical Association found that nearly two-thirds of U.S. adults distrust official government data — a level of skepticism that cuts against both partisan lines and the actual track record of agencies like the Bureau of Labor Statistics and Census Bureau. Trust was higher among frequent data users, suggesting the gap may — like MANY things in public opinion (including AI) — partly reflect unfamiliarity rather than informed disagreement. (NORC / AmeriSpeak)
People who use AI chatbots daily are 30% more likely to show depressive symptoms. A study of nearly 21,000 U.S. adults found a dose-response relationship between personal chatbot use and depression — the more frequent the use, the stronger the symptoms. The effect did not appear for AI used for work or school, only personal use. Whether chatbots are causing depression or attracting already-distressed users remains an extremely important confound and deserves further study. (Baum et al. / JAMA Network Open)
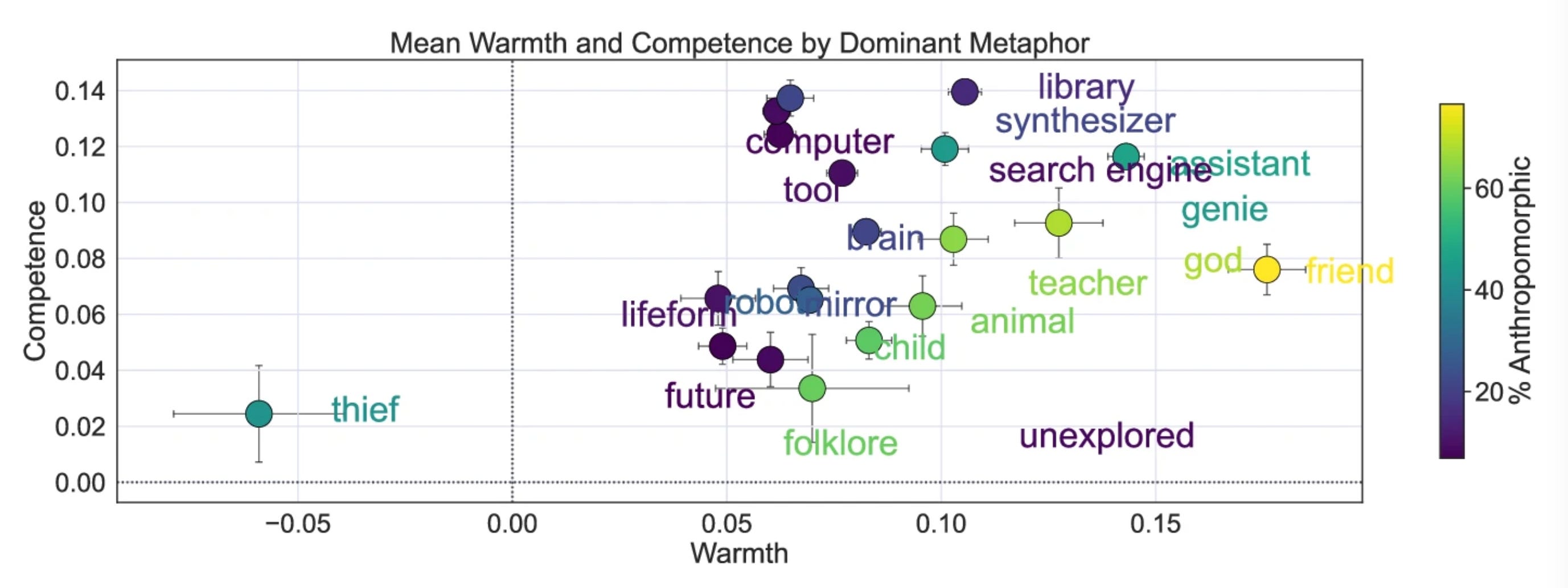
How people “metaphorize” AI is shifting (in a friendlier direction) and strongly predicts whether they'll trust it. Analyzing over 12,000 open-ended metaphors from a year-long nationally representative U.S. survey, researchers found that Americans increasingly describe AI in warm, human-like terms — “assistant,” “friend,” “teacher” — rather than cold mechanical ones. The metaphor someone uses turns out to be a strong predictor of trust and adoption: “thief” strongly predicts rejection, while “brain” and “god” predict higher trust and more use. (Cheng et al. / Nature Communications Psychology)
Two-thirds of Americans support baby bonds, but there is a large partisan gap. A nationally representative survey found that 67.6% of U.S. adults back government-funded investment accounts for children from low-income families — a level of cross-party support that might seem surprising given current political dynamics. Democrats are in near-consensus (81.7%), while Republican support sits at 48%, a majority even among the party most skeptical of government spending programs. Note that baby bonds are different from Trump accounts. (Ettman, Anderson et al. / JAMA Network Open)
LLMs used as synthetic survey respondents have a distorted belief structure compared to real humans. Researchers compared 28 LLMs to the 2024 General Social Survey across 52 attitude items and found that LLM personas exhibit substantially higher attitudinal constraint than actual people — meaning their opinions cluster together more tightly and predictably. The models also overemphasize the dominant attitudinal dimension while missing secondary structure. Variance matters, folks! (Barrie et al.)
Women are far more likely than men to be making tradeoffs to afford healthcare in a variety of areas. As enhanced ACA subsidies expired, a NORC survey found that 77% of women — versus 62% of men — expect 2026 health care costs to strain their household finances. Among likely behavioral responses, women are significantly more likely to report cutting back on food quality (29% vs. 17%), reducing leisure (36% vs. 23%), or taking on additional work (25% vs. 13%). (NORC / AmeriSpeak)
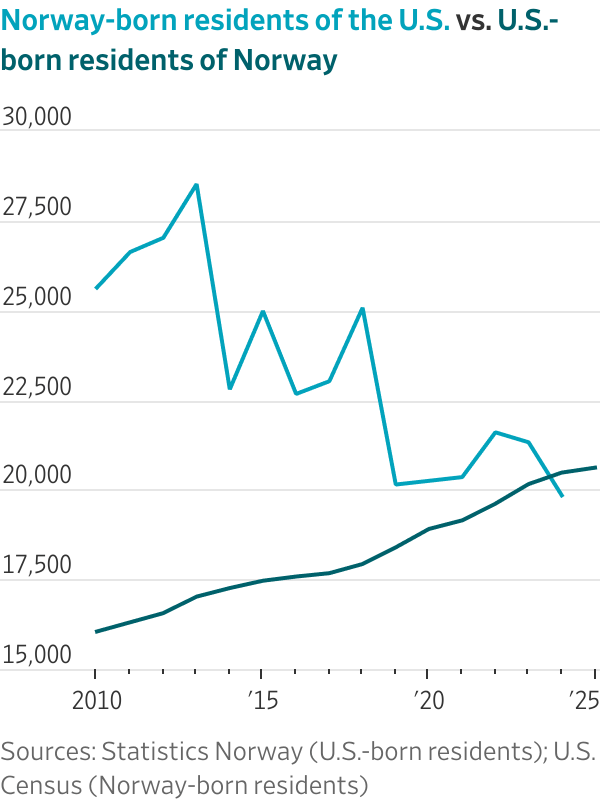
More Americans now live in Norway than Norwegians live in the U.S. Data on American emigration to Europe shows sharp upticks across multiple countries — France, Ireland, Portugal — with the U.S.-born population in Norway now crossing above the Norway-born population in the United States. (Schubert / Brookings)
Chinese social media went viral explaining American financial precariousness using gaming metaphors. The “kill line” — borrowed from video games, where characters below a health threshold can be instantly killed — has been widely adopted on Chinese platforms to describe U.S. economic conditions: roughly 67% of Americans live paycheck to paycheck, and 59% could not cover a $1,000 emergency.
By contrast, the “soft lock” describes a game state where progress is blocked without realizing it, applied to stagnation in China's own economy. The viral spread represents a significant shift in how Chinese audiences are framing comparisons between the two systems, neither particularly ideal. (The Economist)
Most college students say their campus is welcoming, but fewer than a third themselves feel welcome. A survey of students across 260+ two- and four-year colleges found that 70% say most students on their campus feel welcomed, valued, and supported. Yet fewer than one in three rate their own social belonging as excellent or above average, and first-generation students report significantly worse personal belonging than their continuing-generation peers. (Inside Higher Ed / Generation Lab)
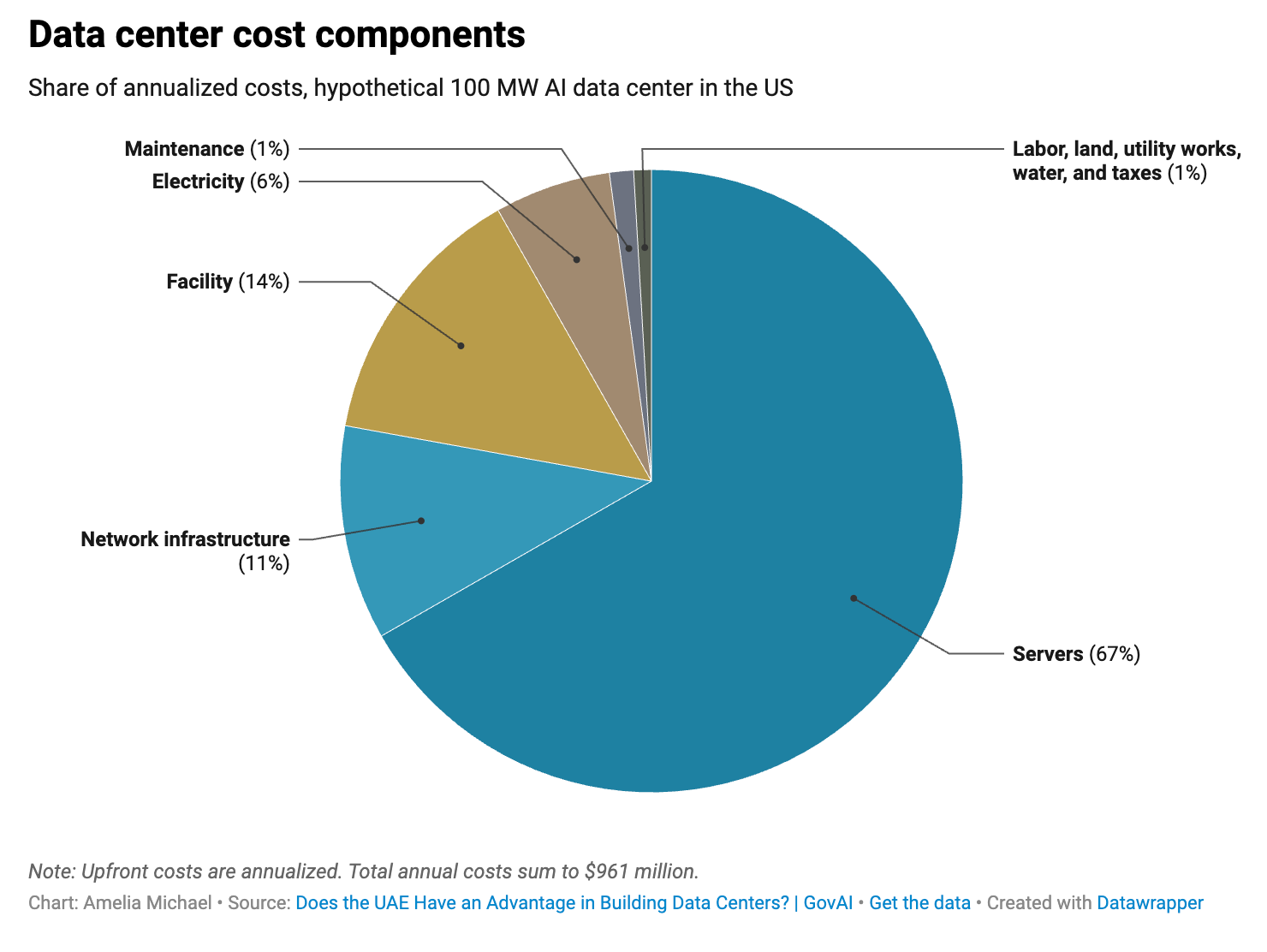
Chips account for two-thirds of what it actually costs to build and run an AI data center. Breaking down the annualized costs of a hypothetical U.S. facility, servers alone represent 67% of total costs and networking infrastructure another 11%. Electricity — the cost most often cited as the data center story — comes in at just 6%. Labor is 0.5%, land 0.3%, water 0.05%. Public discourse around power consumption and land use as the binding constraints on AI buildout may be looking at the wrong line items. (Amelia Michael / Amelia's Substack)
Everything is obvious, nothing is surprising (AI edition)
What is actually surprising any more? Certainly a common refrain in these times is “that doesn’t surprise me at all”.
Duncan Watts famously wrote that everything is obvious once you know the answer. One interpretation of this is that what is surprising depends on what you already expect or know — in other words, your context.
Here’s a little experiment (very much lowercase “e”) trying to gauge what is ‘surprising’ to entities with several orders of magnitude of more context than you or I.
I simply posed the following question both GPT 5.4 and Sonnet 4.6:
Which single finding described in my Substack post is the most surprising to a reasonably informed person? Which single findings is the least surprising? Give at most 2 sentences explaining your reasoning of each.
I repeated this process allowing for extended thinking from both models.
The winner for most surprising finding were tied between “more Americans now live in Norway than Norwegians live in the U.S.” (GPT 5.4, Sonnet 4.6) and “chips account for two-thirds of AI data-center costs” (GPT 5.4-Extended, Sonnet 4.6-Extended). As for why, this is what the models had to say about the first:
Sonnet 4.6: “The directional inversion is the surprising part — most people have a rough mental model of European-to-American migration, not the reverse crossing a threshold.”
GPT 5.4: “…cuts against a very durable mental model of migration as flowing mostly toward the United States.”
…and the second:
Sonnet 4.6-Extended: “…because it directly inverts the dominant public narrative. A reasonably informed person following AI infrastructure coverage would almost certainly rank power consumption as the primary constraint, not server hardware.”
GPT 5.4: “For a reasonably informed person, the dominant public story is that AI infrastructure is mainly a power-and-water story, so a cost structure this lopsided toward servers and networking cuts against the usual mental model.”
As for the least surprising finding, all four model variants unanimously agreed on “women are far more likely than men to be making tradeoffs” (GPT 5, GPT 5.4-Extended, Sonnet 4.6, Sonnet 4.6-Extended). Some comments included:
GPT 5.4: “…many informed readers would already expect women to report greater financial strain around healthcare.”
GPT 5.4-Extended: “A reasonably informed person already knows women tend to bear more healthcare, caregiving, and household budget pressure, so the direction of this finding is not very shocking.”
Sonnet: “The gender gap in healthcare cost exposure is well-documented.”
It is interesting that simply resampling with extended thinking can produce different answers. But the question was not actually what LLMs themselves think; it is what they infer a reasonably informed person would think — so sampling from whatever internal representation of that concept the model has constructed, which may itself be biased, unstable, or even ill-defined. In some situations this inferred perspective could be more or less biased than that of an actual human, raising broader questions about the use of LLMs to curate information.